软件介绍
腾讯IMA(智能工作台)是腾讯于2024年11月推出的AI生产力工具,定位为“会思考的知识库”。它基于混元大模型+RAG架构构建,深度融合微信生态,支持调用超500万篇公众号优质内容,成为中文场景下知识管理的颠覆性产品。 与其他AI产品不同,IMA创新性地整合“搜-读-写”全流程:用户可通过双模型引擎(混元+DeepSeek-R1)实现跨模态内容解析,从微信公众号、本地文件、网页等多源获取信息,并构建个性化知识图谱。其核心价值在于解决信息碎片化痛点——将散落于微信收藏、本地文档、网络文章的知识结构化沉淀,形成可动态调用的“第二大脑”。欢迎大家前来下载体验这款智能工作平台!

直接调用500万+公众号内容库,行业覆盖率第一,如搜索“3号线运营”自动关联北京/重庆等地方信息。
2. 双引擎智能调度:
混元模型擅长中文创作与脑图生成,DeepSeek-R1(免费不限次)强于数学推理与长文本处理,用户可按场景切换。
3. 动态知识图谱构建:
“边问边记”功能自动将问答内容关联存储,形成可追溯的知识网络。
4. 企业级协作架构:
共享知识库支持100万成员协作,权限分级精细到“仅查看/可编辑/可管理”三级。
5. 全终端无缝衔接:
PC端解析1000页文献→生成摘要→保存至知识库→手机端调取核心结论向客户演示。
6. 本地化超强适配:
中文长文本处理优化(实测响应速度超竞品1.7倍),尤其适合政策解读、合同分析等场景。
目前仅支持单库,但可通过“#标签”模拟分类(如#项目A)。官方反馈已在开发多库功能。
Q2上传文件后AI无法识别内容?
检查格式兼容性:PDF/Word/图片≤100M,页数≤500页。如遇扫描件,需开启OCR按钮。
Q3为什么回答混入无关公众号内容?
提问时关闭“全网搜索”选项;或在问题开头声明“仅基于我上传的文档回答”。
Q4是否支持聊天记录导入?
暂不支持。变通方案:微信中长按聊天→收藏→从收藏夹导入IMA知识库。
腾讯IMA使用方法
1、收藏知识,搭建你的第二大脑
① 上传PDF、DOC、JPEG、PNG等格式的内容至知识库
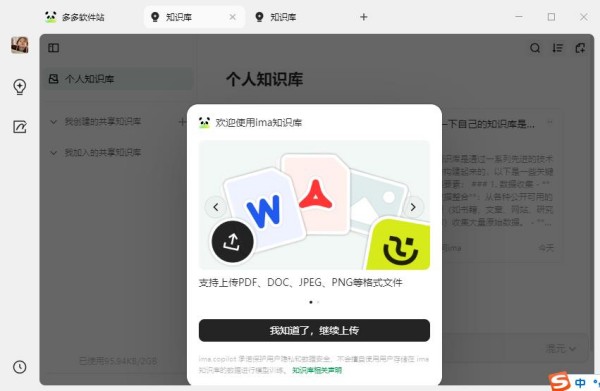
② 浏览网页、进行问答、记笔记时都能随时收藏
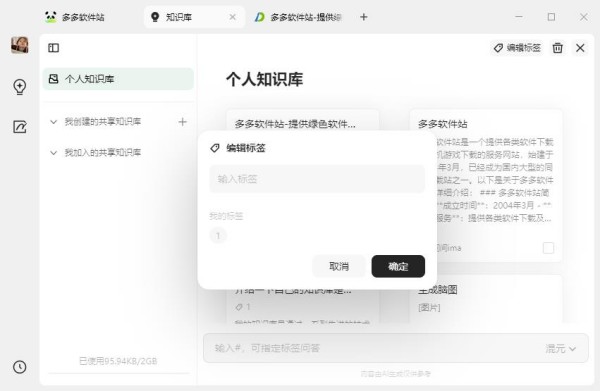
2、管理知识,利用标签便捷分类
① 为知识打上标签,更便捷管理它们
② 在知识库搜索框输入关键词,即可回溯找寻知识灵感
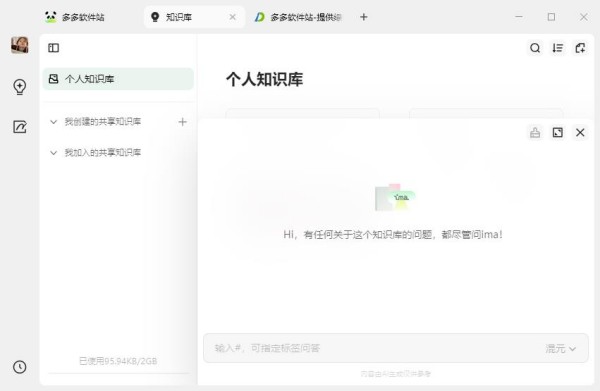
3、应用知识,获得个性化回答
ima可以聚焦于知识库内容,输出更个性化的回答
① 提出问题,获取基于个人知识库内容的回答,温故而知新
② 输入#选择标签,获取基于指定标签下内容的回答
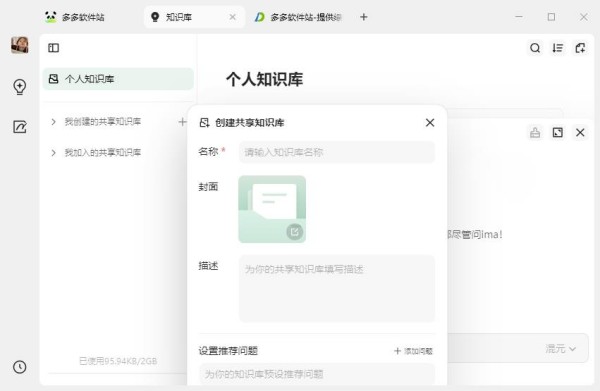
4、共享知识,让知识流动起来
创建不同主题的共享知识库
① 为你的共享知识库添加专属名称、封面和描述
② 从个人知识库、本地文件中导入内容,构建共享知识库
将共享知识库分享给更多人
① 通过分享链接、二维码,将共享知识库分享给他人
② 进行共享知识库的成员管理、设置内容查看权限等
腾讯IMA知识库特点
1. 微信生态独占整合:直接调用500万+公众号内容库,行业覆盖率第一,如搜索“3号线运营”自动关联北京/重庆等地方信息。
2. 双引擎智能调度:
混元模型擅长中文创作与脑图生成,DeepSeek-R1(免费不限次)强于数学推理与长文本处理,用户可按场景切换。
3. 动态知识图谱构建:
“边问边记”功能自动将问答内容关联存储,形成可追溯的知识网络。
4. 企业级协作架构:
共享知识库支持100万成员协作,权限分级精细到“仅查看/可编辑/可管理”三级。
5. 全终端无缝衔接:
PC端解析1000页文献→生成摘要→保存至知识库→手机端调取核心结论向客户演示。
6. 本地化超强适配:
中文长文本处理优化(实测响应速度超竞品1.7倍),尤其适合政策解读、合同分析等场景。
常见问题解决方法
Q1个人知识库能否分类管理?目前仅支持单库,但可通过“#标签”模拟分类(如#项目A)。官方反馈已在开发多库功能。
Q2上传文件后AI无法识别内容?
检查格式兼容性:PDF/Word/图片≤100M,页数≤500页。如遇扫描件,需开启OCR按钮。
Q3为什么回答混入无关公众号内容?
提问时关闭“全网搜索”选项;或在问题开头声明“仅基于我上传的文档回答”。
Q4是否支持聊天记录导入?
暂不支持。变通方案:微信中长按聊天→收藏→从收藏夹导入IMA知识库。
-
 220M 简体中文 2025-07-21
220M 简体中文 2025-07-21
相关文章






























