软件介绍
Ollama 2025版是开源社区推出的跨平台大语言模型运行框架,其核心价值在于将前沿AI能力私有化落地。作为轻量化部署工具,它支持Llama 3、Mistral、DeepSeek-R1等30+主流模型,通过独特的Modelfile打包技术,实现模型权重、配置文件与运行环境的一体化封装。这种设计使开发者能在普通PC上运行70B级模型,突破云端依赖的限制。在技术架构上,Ollama采用动态内存管理技术,通过内存映射(Memory Mapping)将模型加载时间压缩至30秒内。针对GPU加速,它支持NVIDIA CUDA和AMD ROCm双生态,配合FlashAttention技术提升token生成速度,在RTX 4090上运行70B模型可达15 tokens/s的吞吐量。

内置模型市场提供可视化界面,支持一键下载Llama3.3、Gemma2等最新模型。用户可通过`ollamalist`命令实时监控已安装模型,使用`ollamarm`快速清理冗余文件。
2.多模态交互系统
突破纯文本限制,支持图像输入(base64编码)和工具调用。例如在医疗场景中,用户可上传X光片并调用诊断工具链,实现影像分析与病理报告生成的闭环。
3.量化推理优化
首创4-bit量化技术,将70B模型显存占用从140GB降至21GB,在16GB显存显卡上实现稳定运行。配合动态上下文窗口调整,可根据任务需求弹性分配计算资源。
4.API生态扩展
提供OpenAI兼容接口,无缝对接LangChain、LlamaIndex等框架。开发者可通过简单代码实现:
python
fromlangchain.llmsimportOllama
llm=Ollama(model="mistral",temperature=0.8)
print(llm("写一篇关于量子计算的科普文章"))
5.资源监控仪表盘
实时显示GPU利用率、显存占用、推理延迟等指标,配合自动内存回收机制,避免因模型膨胀导致的系统崩溃。
6.安全沙箱机制
新增模型隔离运行环境,通过SELinux/AppArmor限制模型对系统文件的访问。针对敏感行业,支持联邦学习模式下的多方数据协同训练。
-温度参数(temperature):0.1-0.5用于严谨任务,0.8-1.2激发创意生成
-上下文窗口(contextwindow):通过--ctx-size4096扩展对话记忆
2.多模型协同
bash
#同时运行代码生成和文本摘要模型
ollamaserve&
ollamaruncodellama&
ollamarunstarling-lm
3.Docker化部署
dockerfile
FROMollama/ollama:latest
COPYmy_model/models/
CMD["ollama","run","my_model"]
4.监控与日志
-查看实时日志:ollamalogs-f
-生成性能报告:ollamastats>report.json
5.移动端适配
-Android用户安装APK后,通过Termux执行LD_LIBRARY_PATH=/data/app/ollama/lib./ollamarunmistral
Ollama安装方法
解压后,运行ollamasetup.exe;
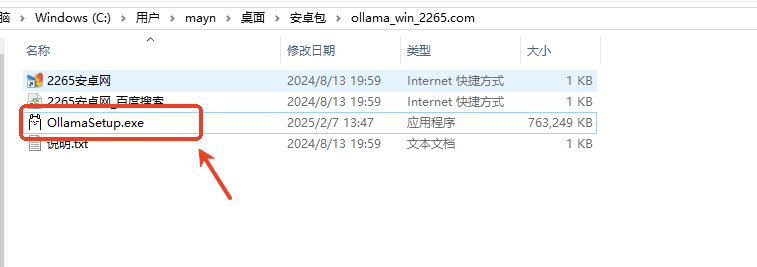
弹出安全警告,点击“运行”;
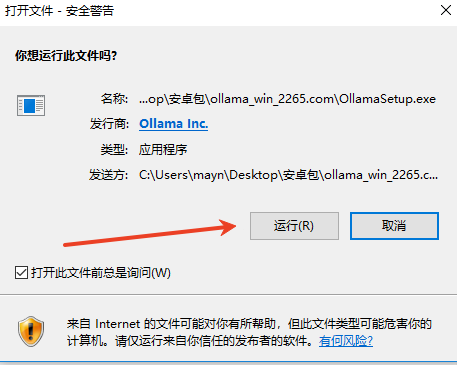
开始安装,点击“install”,片刻后就能安装完成。
开始部署
如搭配DeepSeek使用,DeepSeek模型版本有许多:比如1.5b、7b、8b、14b、32b、70b 671b,版本越高越强大,但是对电脑GPU要求也越高。根据你电脑的配置选择合适的版本,每一个版本都对应一个安装命令,把它复制下来。
DeepSeek-R1
ollama run deepseek-r1:671b
DeepSeek-R1-Distill-Qwen-1.5B
ollama run deepseek-r1:1.5b
DeepSeek-R1-Distill-Qwen-7B
ollama run deepseek-r1:7b
DeepSeek-R1-Distill-Llama-8B
ollama run deepseek-r1:8b
DeepSeek-R1-Distill-Qwen-14B
ollama run deepseek-r1:14b
DeepSeek-R1-Distill-Qwen-32B
ollama run deepseek-r1:32b
DeepSeek-R1-Distill-Llama-70B
ollama run deepseek-r1:70b
然后在CMD命令框,输入上述命令。例如:ollama run deepseek-r1:1.5b,便可以自动在线部署安装。
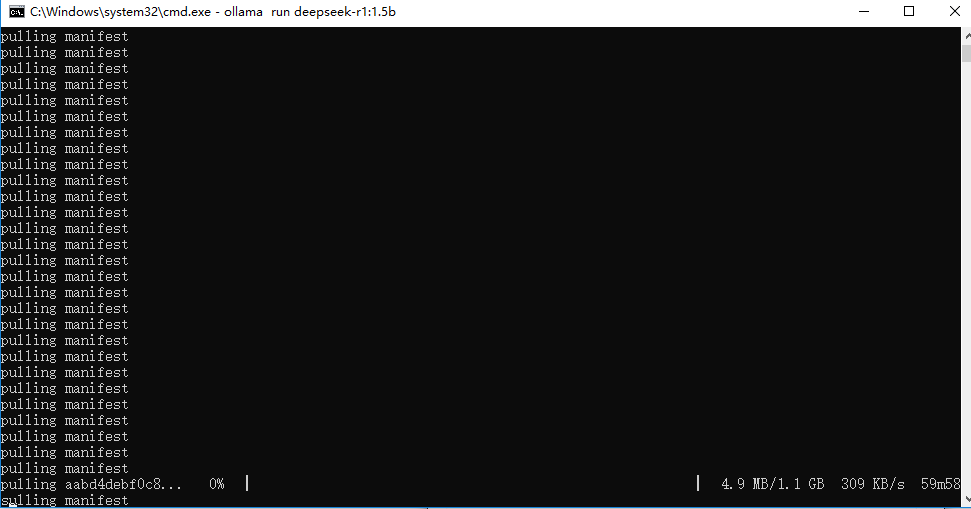
部署成功后,我们可以使用命令窗口直接输入你想问的问题。
Ollama特色
1.模型仓库智能管理内置模型市场提供可视化界面,支持一键下载Llama3.3、Gemma2等最新模型。用户可通过`ollamalist`命令实时监控已安装模型,使用`ollamarm`快速清理冗余文件。
2.多模态交互系统
突破纯文本限制,支持图像输入(base64编码)和工具调用。例如在医疗场景中,用户可上传X光片并调用诊断工具链,实现影像分析与病理报告生成的闭环。
3.量化推理优化
首创4-bit量化技术,将70B模型显存占用从140GB降至21GB,在16GB显存显卡上实现稳定运行。配合动态上下文窗口调整,可根据任务需求弹性分配计算资源。
4.API生态扩展
提供OpenAI兼容接口,无缝对接LangChain、LlamaIndex等框架。开发者可通过简单代码实现:
python
fromlangchain.llmsimportOllama
llm=Ollama(model="mistral",temperature=0.8)
print(llm("写一篇关于量子计算的科普文章"))
5.资源监控仪表盘
实时显示GPU利用率、显存占用、推理延迟等指标,配合自动内存回收机制,避免因模型膨胀导致的系统崩溃。
6.安全沙箱机制
新增模型隔离运行环境,通过SELinux/AppArmor限制模型对系统文件的访问。针对敏感行业,支持联邦学习模式下的多方数据协同训练。
使用技巧
1.模型性能调优-温度参数(temperature):0.1-0.5用于严谨任务,0.8-1.2激发创意生成
-上下文窗口(contextwindow):通过--ctx-size4096扩展对话记忆
2.多模型协同
bash
#同时运行代码生成和文本摘要模型
ollamaserve&
ollamaruncodellama&
ollamarunstarling-lm
3.Docker化部署
dockerfile
FROMollama/ollama:latest
COPYmy_model/models/
CMD["ollama","run","my_model"]
4.监控与日志
-查看实时日志:ollamalogs-f
-生成性能报告:ollamastats>report.json
5.移动端适配
-Android用户安装APK后,通过Termux执行LD_LIBRARY_PATH=/data/app/ollama/lib./ollamarunmistral
-
 1,002.7MB 简体中文 2025-04-29
1,002.7MB 简体中文 2025-04-29
相关文章





























